Hi folks, this is CCS.
There’s a moment, as a filmmaker, when you stop trying to describe a performance with words and start asking: what if the model could just hear it?
That’s exactly what Workflow 17 (attached at the bottom of this page) is built around. Not just video. Not prompts alone.
Audio-guided video generation — feeding a real sound file directly into the model and letting it shape the motion, the timing, the emotional charge of every frame it generates.
This kind of setup opens doors that text prompts alone simply cannot reach.
What You Can Actually Do With This
Let’s be concrete, because this is a workflow that sounds abstract
until you see what it enables in practice…
Below is a snippet of Hamlet’s famous monologue (an extract from a longer clip I’ll share in an upcoming ‘advanced’ post) created using this workflow.
Also included is a short excerpt from a music video demo built entirely on this pipeline. (Track produced by CCS—that’s me! 😉)
You have an image. You have a voice — synthesized, sampled, cloned. You feed both into LTX-2.3, and the model generates a video of that character moving with, and reacting to, the audio. Not randomly — with a degree of synchronization that, combined with a tight prompt, makes it feel intentional. Directed.
This is the part that changes how you think about AI video: you’re not generating motion hoping it looks right. You’re directing a performance. Your prompt tells the character what to do. The audio shapes how they do it. The model bridges the two.
One of the most immediately useful applications: a character delivering a line of dialogue — lips moving, expression shifting, the whole body subtly alive — driven by a real voice recording you’ve prepared in advance. Not perfect lip-sync in the algorithmic sense, but something closer to a human performance than static generation gives you.
Other scenarios this workflow handles well:
– Music video fragments — a figure reacting cohesively to a musical cue, rhythm shaping the motion
– Cinematic narration — a scene that breathes and moves with a voice-over track
– Expressive portraits — characters whose subtle micro-motion tracks vocal energy, pause, breath
The key detail here — and it’s worth emphasizing before we get into the workflow — is that LTX-2.3 is unusually sensitive to the prompt. It has a level of instruction-following that very few video models match. Combined with audio guidance, that means both channels reinforce each other. A precise prompt describing the action plus a real audio track pointing at the same performance gives you compounding control over what gets generated.
If you want a dedicated deep-dive on prompt writing for LTX — how to phrase motion, performance, and scene in ways the model actually responds to — it’s covered in this post: [VID] LTX-2.3 PROMPTING MASTERCLASS — DIRECTING THE LTX-2.3 MODEL (Patreon supporters)
For the complete setup, including model downloads and installation paths, please refer to this post: [VID] LTX-2.3: The New King of AI Video? 🚀 Full Workflow & Test | Patreon
The Workflow at a Glance
The workflow takes two primary inputs:
1. An image — your character, scene, or subject
2. An audio file — voice, music, score, sound design, anything with waveform data
It outputs a video in which the model has been conditioned on both simultaneously.
The image anchors what it looks like. The audio shapes what it does.
How the Audio Actually Works
Here’s what most guides skip — and it’s the thing that makes this fundamentally different from generating video and then syncing audio on top afterward.
The audio doesn’t sit beside the video. It lives inside the same latent space.
LTX-2.3 was trained as a joint audio-visual model. That means it learned what video and audio look like together, not separately. When you run this workflow, the process goes like this:
1 — Audio encoding.
Your audio file gets compressed into a structured representation — a latent — the same way a photograph gets encoded before a diffusion model works on it. After this step, the model no longer sees a sound file. It sees structured data shaped to fit alongside video data.
2 — Latent fusion.
The audio latent and the video latent are merged into a single, unified structure. From this point on, the sampler is operating on something that contains both what the scene looks like and what it sounds like — as one object.
3 — Joint denoising.
The diffusion process runs over this fused structure. Every step the model takes is simultaneously aware of the audio. It doesn’t generate the video first and condition on audio afterward — it generates them together, as a single coherent decision.
4 — Separation and decode.
After sampling completes, the joint result is split back apart. The visual component is decoded into frames.
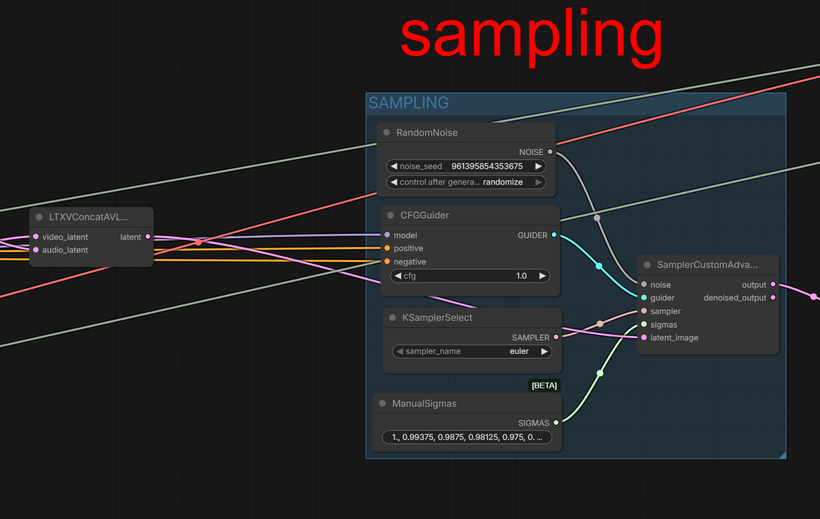
the model receives the fused audio+video latent and denoises both at once.
The result: generated motion that has been shaped by the rhythm and energy of the audio. High-energy vocal moments tend to produce more movement. Pauses produce stillness. Musical phrases produce their own kind of visual phrasing. This isn’t programmed — it’s what the model learned from training on paired data.
Add a prompt that describes the specific action happening in the audio, and both signals point at the same target. That’s when the generations feel directed.
What To load and where
The workflow is straightforward to run:
– Load Image — your portrait, character, or scene
– Load Audio — the voice or music that will guide the generation
– Set frame count — size your clip to match the audio duration (LTX’s 8n+1 frame rule applies: valid values are 25, 33, 41, 49… — the workflow handles this automatically)
– Write your prompt — be specific about what the character is doing. If they’re speaking, say so. If reacting to music, describe how. LTX obeys.
image anchors the visual — audio anchors the motion.
One practical note on prompting: the gap between a vague prompt (“a woman”) and a precise one (“a woman speaking softly, head tilting slightly, lips parting, eyes focused”) is significant when audio guidance is involved. Both channels become load-bearing. Spend time on the prompt.
DECODING PART… HIGH OR LOW VRAM?
The final part of the pipeline is the Decoding block. I’ve provided two options: one for Normal/High VRAM and a specialized ‘VAE TO DISK’ path for Low VRAM setups. Just connect your preferred decoder and bypass the unused one using Ctrl+B
Beyond the Single Clip
Workflow 17 generates a single segment — one clip, one audio chunk, one pass. It’s the foundation.
If you want to generate the voice itself inside the workflow (text → speech → video in one pipeline), that’s what the coming soon LTX-2.3 AU+IMG2VID advanced workflow (17B) is built for. It adds a complete AI audio generation layer on top of this same foundation: TTS, voice cloning, ASR transcription verification.
More soon.
— CCS